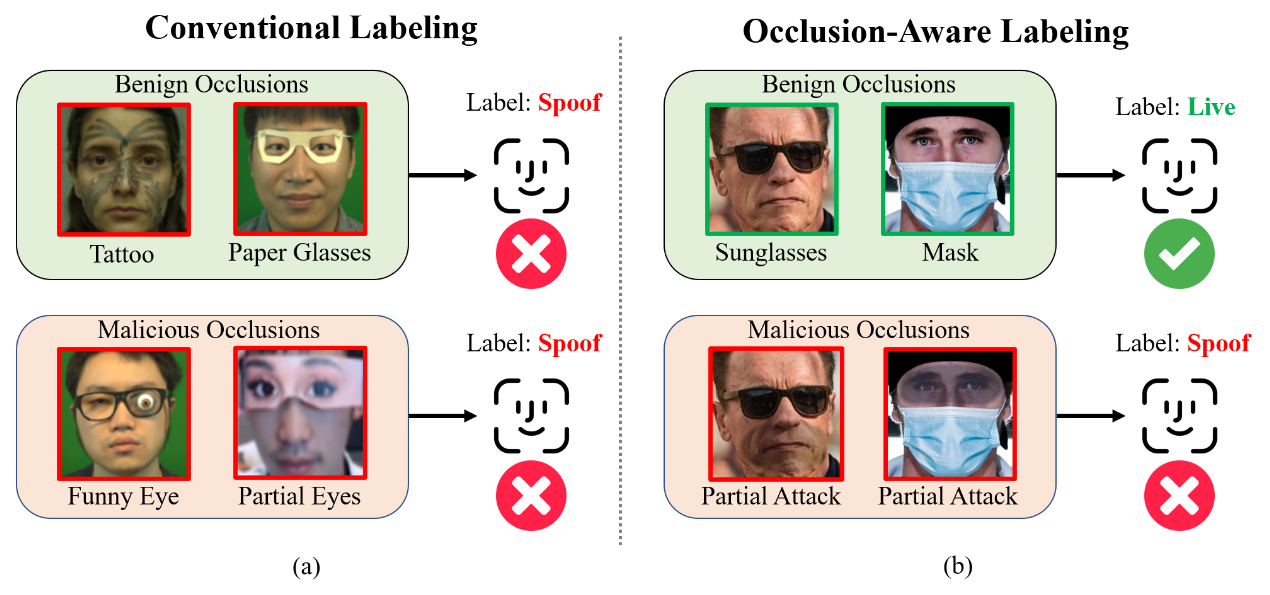
OCC-FAS reframes occluded face anti-spoofing by treating benign accessories as valid live presentations while isolating malicious spoof cues in full and partial attack settings.
Occlusion-aware labeling
Masks and sunglasses are modeled as real-world live conditions, not automatic spoof evidence.
Partial-attack coverage
Six scenarios span live, full spoof, spoofed occlusion, real occlusion, and hybrid live-spoof cases.
Spatial supervision
Spoof cue maps and occlusion maps provide pixel-level ground truth for localized liveness learning.